|
|
|
|

|
|
|
Блоки адресации, выборки и фильтрации текстур | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Игорь Лагунов (Buntar) 15.11.2007
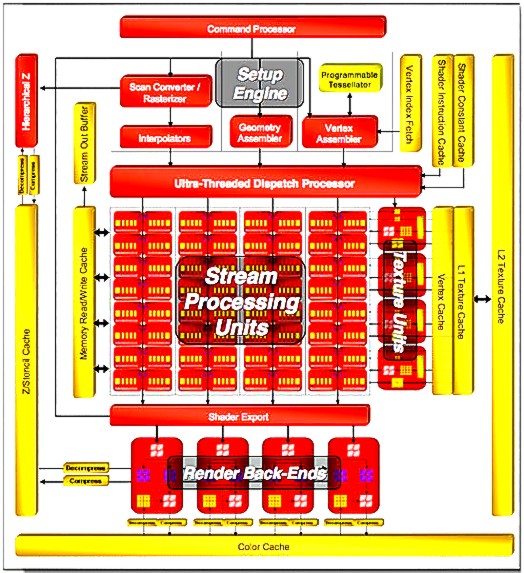
Более подробно ознакомиться с 3D терминологией можно в статье Ликбез по 3D. Немного историиТрудно переоценить значение специализированных блоков загрузки и фильтрации текстур в составе архитектуры современного графического процессора. Собственно, аппаратное ускорение 3D-графики на персональных компьютерах началось именно с их появления. Первый удачный 3D-акселератор для массового рынка, Voodoo Graphics, был двухчиповым решением. Один чип, TexelFX, представлял собой один простой текстурный блок, загружавший четыре текселя и выполнявший билинейную интерполяцию между ними за один такт. Другой чип, PixelFX, являлся простым блоком растеризации (ROP), выводящим один пиксель за такт. В Voodoo 2 был добавлен второй текстурный блок, что позволило применять несколько более сложные эффекты, накладывая до двух текстур на пиксель за такт. Либо, если игра не поддерживала мультитекстурирования, включать трилинейную фильтрацию. На периодически добавляющейся поддержке увеличенных размеров и новых форматов текстур в этой статье внимание заострять не будем. Следующим важным нововведением стало появление возможности однопроходного мультитекстурирования - до двух текстур за проход силами одного текстурного блока на конвейер в Rage 128. Тот чип имел текстурный и пиксельный кеши, по 8 КБ каждый, что позволило сохранять между тактами промежуточные результаты рендеринга с полной точностью и без задержек, связанных с записью в видеопамять. Этой модели последовали и другие производители, и дальше мы видели увеличение количества накладываемых текстур за проход, увеличение количества конвейеров рендеринга, добавление полноценных блоков T&L и увеличение сложности эффектов, реализуемых различными методами одновременного накладывания нескольких текстур. Добавление поддержки продвинутых эффектов типа попиксельного освещения, рельефного текстурирования с использованием карт окружения и им подобных, привело к появлению программируемых АЛУ, привязанных к текстурным блокам. Чуть позже наступило время полностью программируемых шейдерных архитектур. Появились программируемые вершинные шейдеры. Сначала процессоры вершинных шейдеров работали параллельно со старыми (fixed-function) блоками T&L, которые выполняли свой фиксированный набор функций эффективнее более гибких вершинных процессоров. Дальнейшее развитие вершинных процессоров позволило полностью отказаться от FF блоков T&L, а текстурные блоки стали частью пиксельных процессоров. Несмотря на постоянное увеличение возможностей и количества программируемых АЛУ, архитектуры графических чипов еще долгое время были чётко разделены на блоки обработки вершинных и пиксельных шейдеров, где пиксельные шейдеры имели почти эксклюзивный доступ к блокам текстурирования. Рассмотрим блоки текстурирования такой архитектуры подробно на примере последнего вышедшего "топового" чипа - R580+. R580+ в качестве примера старой архитектуры
R580+ имел 48 пиксельных процессоров, распределенных по четырем SIMD-квадам (пиксельные процессоры одного квада выполняли одни и те же инструкции, но над разными пикселями). При этом, внутри квадов они были сгруппированы в группы по 3. К каждой группе был привязан свой текстурный блок, который получал инструкцию одновременно со своей группой пиксельных процессоров. Текстурный блок мог выбирать до четырех текселей и выполнять одну билинейную интерполяцию за такт до 16-ти раз за проход. Поддерживалась адресация текстур размером до 4096х4096. Поддерживались сжатые форматы DXTC/S3TC 1-5 и 3DC+. Отличие 3DC+ от 3DC, в дополнение к 4:1 компрессии двухканальных текстур, заключается в поддержке 2:1 компрессии одноканальных текстур, которые могут быть использованы для карт освещения или затенения, для хранения свойств материалов и т.п.. Конечно же, можно было выполнять анизотропную фильтрацию степенью до 16х. На том этапе в ATI считали, что основным применением для текстур в формате с плавающей запятой будет хранение таблиц данных, поэтому для них аппаратно поддерживалась только поточечная выборка. Выборка из FP16 текстуры выполнялась за два такта, из FP32 текстуры - за 4. Программист мог реализовать их фильтрацию в шейдере, соответственно теряя в производительности. Учитывая соотношение 3:1 количества пиксельных процессоров к количеству текстурных блоков, в чипах ATI, начиная с RV530, была введена поддержка технологии под названием Fetch4, призванной ускорить выборку из одноканальных текстур в 4 раза.
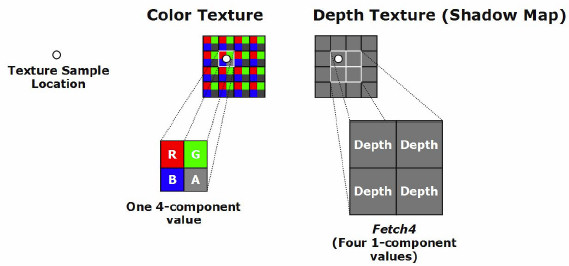
Обычные текстуры являются четырёхканальными (красный, зелёный, синий цвета и альфа-канал). Fetch4 использует 4 канала RGBA для одновременной выборки из четырёх текселей одноканальной текстуры. Основное применение этой технологии видится в чтении карт теней и в последующем усреднении значений затенённости в пиксельном шейдере. Отдельно остановимся на вопросе доступа к текстурам из вершинного шейдера. SM3.0 требует возможность текстурирования в вершинном шейдере, в то время как WHQL сертицифицированный R580+ не имел никаких специальных узлов для доступа к текстурам из вершинных процессоров. Этот факт породил немало недоумений о неполном соответствии R580+ спецификациям SM3.0. Все дело в том, что хотя бит возможности текстурирования в вершинном шейдере и должен быть включен, спецификация SM3.0 не диктует каких-либо форматов текстур, которые должен поддерживать вершинный процесор. Этой брешью в спецификации успешно пользовался R580+, проходя все SM3.0 тесты Microsoft. ATI осознанно не стала внедрять модули текстурирования в вершинные процессоры. Внедрение полноценных блоков для адресации, выборки, фильтрации и кеширования текстур в каждый из 8-ми вершинных процессоров потребовало бы слишком много места на кристалле, либо сокращая функциональность других блоков графического контроллера, либо лимитируя его частотный потенциал. Внедрение простых текстурников с минимальной функциональностью, как было сделано, например, в NV40, ATI также сочла нерациональным. Позиция ATI в этом вопросе выглядит особенно убедительно в свете вскоре свершившегося перехода на унифицированную архитектуру, где вершинные и пиксельные шейдеры выполняются одними и теми же функциональными блоками, и вершинные шейдеры, наконец, получили прямой доступ к мощным текстурным модулям, ранее используемым только пиксельными процессорами. В действительности, использовать текстурные модули пиксельных конвейеров в вершинных шейдерах можно было уже тогда. Результат пиксельного шейдера может быть записан не только в кадровый буфер или в текстуру, но и в вершинный буфер - буфер в памяти, используемый в качестве ввода для вершинного шейдера. ATI продвигали использование расширения Render To Vertex Buffer (R2VB) для DirectX в качестве альтернативного метода текстурирования в вершинном шейдере. По идее, любой DirectX9 (включая SM2.0 и не-ATI) графический контроллер был способен поддерживать рендеринг в вершинный буфер, все зависело только от желания или нежелания производителей включить поддержку R2VB в драйвере. R2VB имел плюсы по сравнению с вершинным текстурированием в его тогдашнем виде. Он позволял использовать всю функциональность пиксельного шейдера в вершинном, и должен был выполняться быстрее, чем традиционное вершинное текстурирование, так как пиксельные процессоры уже были созданы с учетом высоких задержек при выборке текстур. Перейдём к блокам текстурирования современных архитектур. Текстурные блоки R600
R600 имеет квартет текстурных блоков, и они теперь почти полностью отделены от вычислительных массивов АЛУ. Единственным ограничением является привязанность каждого текстурного блока к своим квадам шейдерных процессоров. Т.е., если представить R600 как 4 массива по 16 шейдерных блоков, то каждый массив представляет собой 4 квада, и каждый текстурный блок загружает данные только в свой квад в каждом из четырёх массивов.
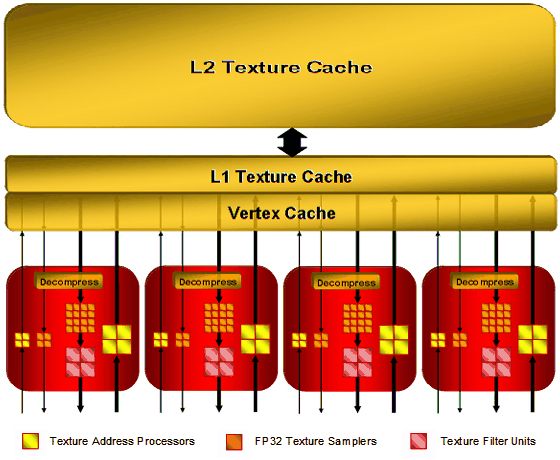
Каждый текстурный блок состоит из 8 блоков адресации, 20 блоков выборки и 4 блоков фильтрации. Обратите внимание, что 4 из 20 блоков выборки предназначены исключительно для поточечной выборки (или для загрузки вершин). Выборка любой текстуры, включая даже FP32, происходит теперь всего за один такт. Т.е., например, каждый текстурный блок способен загрузить достаточно FP32 текселей для четырёх билинейных фильтраций и ещё 4 FP32 текселя для поточечной выборки, и всё за один такт. Блоки фильтрации теперь способны аппаратно фильтровать любые форматы текстур. Причём, большинство форматов билинейно фильтруются также за один такт. Исключение составляют только два самых "тяжёлых" формата - четырёхканальные INT16 и FP32 - на фильтрацию которых уходит два такта. Текстурный блок может наложить до 128 текстур за проход. Была добавлена поддержка адресации 8192х8192 текстур, а также нового 32-бит RGBE (9:9:9:5) формата. По-прежнему поддерживается Fetch4, и появилась поддержка PCF (Percentage Closer Filtering), благодаря её включению в DirectX 10. PCF долгое время оставалась проблемой для ATI, т.к. она не была документирована в DirectX и вообще являлась интеллектуальной собственностью SGI, доступ к которой nVidia получила путём специального соглашения. Тем не менее, технология смогла получить широкую поддержку в играх, благодаря использованию NV2A в игровой приставке XBOX, где поведение PCF было хорошо известно разработчикам. Реализация технологии сходна с применением Fetch4 для сглаживания теней, за исключением того, что PCF усредняет значения текселей аппаратно блоком фильтрации текстур. Текстурные блоки имеют L1 кеши по 32 КБ каждый, вершинный кеш может использоваться для ускорения поточечных выборок (у RV610 вершинный и L1 кеши сложены в один), размер L2 кеша равен 256 КБ у R600 и 128 КБ у RV630 (RV610 не имеет L2 текстурного кеша). Текстурные блоки управляются выделенным арбитром. Одновременно может быть запущено множество потоков, чтобы блоки выборки и фильтрации (как следствие и шейдерные процессоры) простаивали как можно меньше времени. Этот арбитр работает совместно с арбитром шейдерных процессоров, который останавливает потоки (отдавая ресурсы другим потокам), ждущие данных от текстурных блоков. Текстурные блоки G80
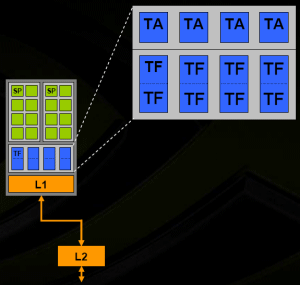
В G80 текстурные блоки всё ещё плотно привязаны к своим кластерам шейдерных процессоров. Это несколько снижает производительность, т.к. процессоры не могут использовать "чужие" текстурники, даже когда те свободны. Каждый текстурный блок состоит из 4 блоков адресации, 8 (32 в терминологии R600) блоков выборки и 8 блоков фильтрации. Выборка из FP16 текстуры выполняется на половинной скорости, из FP32 текстуры - в четыре раза медленнее, чем выборка INT8. Блоки фильтрации способны аппаратно фильтровать любые форматы текстур. Некоторые примеры возможностей: каждый текстурный блок способен либо выполнить 4 билинейные AF 2x с форматом INT8 (да, бесплатная AF 2x, если нужные тексели оказались в L1 кеше), либо 4 билинейные фильтрации с форматом FP16, либо 2 билинейные фильтрации с форматом текстуры FP32. Текстурный блок может наложить до 128 текстур за проход. Текстурные блоки имеют L1 кеши по 8 КБ каждый. L2 кеш, объём которого равен 128 КБ, текстурные блоки делят с блоками ROP. По всей видимости, текстурные блоки G80 используются для доступа к буферам констант шейдерными процессорами, что может негативно сказаться на производительности DirectX 10 приложений. Текстурные блоки G80 также управляются арбитрами отдельно от шейдерных процессоров. В чипах G84 и G92, появившихся после G80, каждый кластер шейдерных процессоров уже включает по 8 блоков адресации текстур. ЗаключениеСравним некоторые пиковые теоретические возможности текстурных блоков R580+, R600 и G80 таблицей.
Хотя R600 значительно отстаёт от G80 по мощности текстурных блоков, в его пользу выступают более крупные кеши, повышенная тактовая частота, а также менее жёсткая привязанность текстурных блоков к конкретным шейдерным процессорам. Но всё же R600 является заметным шагом вперёд по сравнению с R580+. Судя по предварительным данным, Fetch4 будет включена в состав DirectX 10.1 под названием Gather4. В отличие от PCF, уже включенной в состав DX 10, это позволит напрямую передавать неотфильтрованные тексели одноканальных текстур блокам АЛУ (PCF передаёт блокам АЛУ только отфильтрованный результат). Начиная с RV530, продукты AMD уже поддерживают Fetch4, а компании nVidia придётся изменить их текстурные блоки для поддержки этой технологии. Краткий глоссарий некоторых терминов, использованных в статье
Благодарности: NEW, ArtLonger, U-Nick, Walter S. Farrell.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| На главную страницу |
Главная | Справочник | FAQ | Статьи | Загрузки | Контакты | Конференция







Александр Ефимов (IdeaFix)