|
|
|
|

|
|
|
«Камо грядеши?» в кремнии. О процессорах и путях, которые мы выбираем. | ||
|
Илья Вайцман (Stranger_NN) 18.02.2017
Оглавление1. Вступление.2. Немного истории, и повесть о том, как мы дошли до жизни такой. 3. Что делать, когда нечего делать? 4. Насколько это эффективно по сравнению с эльбрустикой? 5. И еще один гвоздь в гроб эльбрустики. Экономический. Вступление.Мне много раз уже писали (кричали, презрительно бросали через губу), что у меня в отношении «российской школы процессоростроения» (детища гр. Бабаяна Б.А.) - голое критиканство, и что я все равно не могу предложить ничего лучшего, чем уже состоявшийся путь развития (приведший «отечественные процессоры» в концептуальный тупик, не оставляющий шансов на дальнейший рост производительности, но об этом ниже). Я, признаться, думал, что господа «патриоты и государственники» немного лучше разбираются в теме, по которой пытаются спорить, и мне казалось, что все настолько очевидно - «как надо было», и как «не надо было», что и говорить не о чем, и это просто истерика. Однако, это оказалось не так - и мне придется потратить час времени и потыкать «патриотов» носом. Немного истории, и повесть о том, как мы дошли до жизни такой.Скажите, вы слышали что-нибудь про архитектуру MIPS? Нет, не надо кидаться в гугл, не слышали. И про SPARC/Ultra SPARC тоже нифига не знаете, даже не пытайтесь возражать. Так вот, докладываю: компания МЦСТ – это, есличо, «Международный центр SPARC-технологий». Потому что в середине 90-х именно SPARC v.8 была выбрана в качестве базовой архитектуры будущего российского процессора. Почему? Ну, полагаю, что из-за своей простоты и небольшого числа транзисторов, из-за нетребовательности к техпроцессу и дешевизны лицензии. И, надо признать, что первые отечественные процессоры получились быстро и с вполне ожидаемыми параметрами. Что дальше? А дальше - всё, приехали. IPC (не путать с теоретической параллельностью!) даже для Ultra SPARC v.9 примерно никакая, так что несмотря на приличные, казалось бы, частоты - итоговая производительность не радует (кстати, именно поэтому компания SPARC и сошла со сцены - ее процессоры застряли на уровне начала 90-х). Собственно, самым быстрым продуктом МЦСТ архитектуры SPARC на сегодня является МЦСТ R1000 который при проектной норме 90 нм имеет производительность 8 GFlops, что примерно соответствует четырехядерному процессору Intel Atom N3540 (в маркетинговых целях его перекрестили в Pentium N3540, но какой же он Pentium? Смех один...). Ну, сами понимаете, что сегодня это самый-самый-самый low-end потребительского рынка. Конечно, такой производительности для всякого военного и встроенного применения хватает, но и только. Усугубляет проблему R1000 и древний интерфейс, с крайне ограниченной ПСП (6,4 GB/s против 21,32 GB/s), и недостаточный размер кэша, так что в алгоритмах с несложным счетом он еще и в память упирается (Есть, конечно, в мире и линейка Venus SPARC64 от Fujitsu, там совсем другие величины производительности в ходу (128 и более GFlops), и даже 32-ядерные вычислители SPARC64 XIfx терафлопного класса - но там от оригинального процессора SUN осталась только, наверное, система команд, для совместимости, при полностью переработанной архитектуре - и они вряд ли продадут лицензию.). Развивать эту концепцию дальше смысла уже просто не было - да и было ли это в планах, кроме как на сайте МЦСТ? Не знаю, но рискну предположить, что одним из факторов выбора этой архитектуры был запланированный тупик «отечественных процессоров», прорыв из которого состоялся на припасенном в рукаве принципиально другом, фактически «анти-SPARC» принципе - сверхшироком (VLIW) низкочастотном процессоре явного параллелизма и чудовищной IPC, каковой принцип унаследован из еще советских разработок. Тогда, из-за глобального отставания советской микроэлектроники частоты, которыми оперировали компьютеростроители «вероятного противника» были недостижимы, вот и придумали делать компьютеры (серии Эльбрус) «более широкие, чем быстрые» (собственно, саму концепцию VLIW придумали конструкторы компании Burroughs Corporation в 70-х, несколько ранее и по той же причине - уперлись в достижимые частоты). Суть идеи явного параллелизма в том, что еще на этапе компиляции (неторопливо и качественно, с большой глубиной просмотра кода) выявляются все зависимости и возможности распараллеливания, после чего команды собираются в «пакеты одновременного исполнения» - слова VLIW, содержащие несколько команд. При этом процессору на этапе исполнения уже не надо ни о чем думать (никаких предсказаний ветвления, никакого переупорядочивания команд, в попытках рационально использовать свои ресурсы на неизвестном коде - ему надо просто тупо «взять и выполнить»). Разумеется, что это существенно упрощает схемотехнику процессора и, теоретически, существенно улучшает использование ресурсов как процессора, так и компьютера в целом. Однако, если западные конструкторы, работавшие над VLIW системами сумели найти какой-то разумный уровень явного параллелизма (в Itanium, к примеру, шесть команд в слове), то наши конструкторы, сделав еще в до-микропроцессорную эпоху парочку пристойного уровня производительности (про надежность не будем) VLIW-машин - остановиться не смогли. И довели ширину слова до 23, а теперь уже и до 25 команд. В принципе, на некоторых алгоритмах, позволяющих хорошо заполнить слово, это позволяет получить совершенно невероятный уровень IPC. В первую очередь, это задачи цифровой обработки сигналов и криптография. Но проблема в том, что полное использование всей ширины VLIW процессора Эльбрус возможно далеко не всегда. Последовательная природа многих алгоритмов не позволяет распараллеливать их исполнение в достаточной степени. Судя по прикидкам «на пальцах», при сравнении производительности с классическими процессорами - средний уровень заполнения командного слова у Эльбрусов болтается где-то на уровне 7-10-12 команд из 23-25 в довольно хорошо параллелящемся тесте LINPACK. Это получается, примерно, 30-50%. Неплохо, конечно, если бы не одно «но».
В итоге мы имеем на сегодня «десктопный» Эльбрус-4С, который с миллиардом транзисторов примерно вдвое (теоретический максимум 251 GFlops - и это на Linpack, не считая сложностей достижения этого максимума на системах с таким уровнем параллелизма в произвольных задачах) медленнее уже устаревшего Core 2 Quad (42-47 GFlops – измерено на практике), причем, процессор Intel еще и вдвое меньше транзисторов имеет (ниже себестоимость). Собственно, на этом все - новейший чудовищный Эльбрус-8С с почти тремя миллиардами транзисторов представляет собой экстенсивный перепил дизайна2 и максимум что может дать, с учетом новой частоты, на новом техпроцессе - 70-80 GFlops, вряд ли больше (обещают 125, но я не верю, потому что это просто арифметический расчет теоретического предела. Если из сотни в реальных тестах выберется - чудо будет). На этом, собственно, все. Дальше расти Эльбрусам просто некуда, а многосокетные системы на них... Ну, наверное, кто-то им может найти применение. Если денег не считать. Что делать, когда нечего делать?Существует ли другой путь, коль скоро титаны Intel и AMD не горят желанием лицензии продавать? Еще как существует, и любой серьезный IT специалист про него знает. По этому пути пошел Китай. Что же наши друзья из Китая? А наши друзья из Китая не стали придумывать способы как обхитрить самих себя два раза, и как изобретать велосипеды. Они с конца 90-х взялись за архитектуру MIPS, известную, как раз, довольно короткими конвейерами и высокими значениями IPC. И уже через пару лет показали процессор Godson-1 архитектуры MIPS32. Простенький камешек, работающий, однако, на частоте 200 MHz и показывающий производительность больше, чем вышедших в то же время российских R100 и R150. А потом понеслось - через год появился 64-разрядный (MIPS-III 64-bit) Godson-2, работавший в два раза быстрее, за четыре года его раскрутили до 1200 MHz получив в 2007 году вполне путный десктопный процессор, сопоставимый по производительности с Pentium4 с частотой 2.4 GHz - но потребляющий всего 5 (пять!) ватт. Помнящие времена раскаленных Pentium4 и связанные с этим проблемы могут оценить. 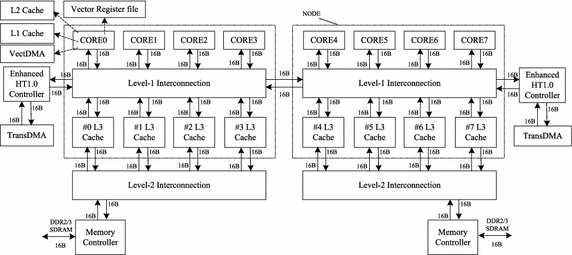 Godson-3B1500 А потом китайцы перешли на архитектуру MIPS64 (заметьте - они снова не разрабатывали архитектуру, и даже уже не пиратствовали, как раньше, а просто лицензировались (через STMicroelectronics) и прикладывали дизайн на техпроцесс, обвешивая ядро стандартными компонентами типа кэшей и контроллеров внешних шин, что на порядок быстрее и дешевле) - и уже в 2012 году имели полуторагигагерцовый процессор Godson-3c с 16 ядрами, примерно двумя миллиардами транзисторов и суммарной производительностью 512(!) GFlops. По 32 GFlops на ядро3, в смысле. Это, конечно, серверный топ, и вообще - почти штучное достижение, но и десктопные процессоры этой архитектуры с меньшим количеством ядер и частотой в один гигагерц показывают вполне достойную производительность при достаточно умеренном потреблении (15 ватт для гигагерцового четырехядерного Loongson 3A с производительностью около 80 GFlops и около 40 ватт для восьмиядерного Godson/Loongson-3B1500 (1350 MHz ) с производительностью 172,6 GFlops). Это, напомню, в 3+ и 6+ раза соответственно - быстрее, чем Эльбрус-4С, а если ориентироваться на Эльбрус-8С, текущее наше высшее достижение - то Loongson 3A ему не уступает, имея вчетверо меньше транзисторов, а Loongson-3B1500, имея транзисторов вдвое меньше - вдвое его обгоняет. Насколько это эффективно по сравнению с эльбрустикой?Давайте сравним архитектуры в разрезе удельной производительности на ватт, на гигагерц и на транзистор. Результаты, прямо скажем, не радуют, с какой стороны ни смотри. Если смотреть на ватт, то результаты выглядят как-то так:
Совершенно очевидно, что даже имея лучший, чем у китайского изделия техпроцесс - Эльбрус с треском ему проигрывает. Несколько неожиданным является отставание в удельной производительности интеловского процессора, имеющего двухкратное преимущество в абсолютных величинах, но тут надо понимать, что из 2,6 миллиардов транзисторов интеловского процессора - значительную часть (около половины) составляют не счетные ядра, а 24 мегабайта кэшей второго (8x512 KB) и третьего (20 MB) уровней, необходимые для работы на частоте, многократно превышающей частоту памяти, чтобы ядра не простаивали. Они же вносят очень существенный вклад в общую TDP. С другой стороны, и у Эльбруса кэша 20 мегабайт (8x512 KB L2 + 16 MB L3) - а толку?! «Эльбрус» демострирует потрясающе низкую энергоэффективность!!! Только что TDP 75-90 ватт.  Китайский же Godson-3B1500 с такой же частотой и существенно большей производительностью обходится всего девятью мегабайтами кэшей второго (8х128 KB) и третьего (8 MB) уровней - что отлично видно по числу транзисторов и TDP 40 ватт (и, опять же, понятно, что с ростом частоты ему будут наращивать размеры кэшей, получая близкий к демонстрируемому процессорами Intel график абсолютной скорости - и по моему мнению, даже существенно обгоняя их при равной частоте). Ему не мешает даже худший техпроцесс, архитектура MIPS справляется.  Loongson 3A1500 Про самые новые китайские процессоры Loongson 3A2000/1500 и 3B1500 на новой архитектуре GS464E информации пока мало, но некоторые публикации говорят, что они, имея примерно такое же количество транзисторов (в пределах полутора миллиардов), показывают с четырьмя5 ядрами уровень производительности в те же 170-180 GFlops, что несильно меньше интеловских десктопных процессоров вышесреднего уровня - и это при сохраняющемся кратно меньшем потреблении энергии (точной информации у меня нет, но исходя из техпроцесса - должны бы ватт в 30-35 вписаться). Собственно, никакого чуда тут нет - им же не надо волочить за собой чудовищный хвост совместимости с процессорами и решениями полувековой давности, так что ничего волшебного.
В полтора раза (при равной частоте) превосходящий результат достигнут на MIPS64 при вдвое меньшем, чем у Эльбруса количестве транзисторов, и при вдвое меньшем потреблении, энергии, несмотря на худший техпроцесс, понимаете? Это приговор всей прикладной и теоретической эльбрустике и рассказам о непревзойденной эффективности VLIW в том виде, в котором ее продвигает МЦСТ. Больше прошу не беспокоить с рассказами про «превосходящую всё существующее и не имеющую аналогов архитектуру «Эльбрус». Это не соответствует действительности, если политкорректно. Почему так? Я думаю, как уже писал выше, что это из-за очень большого недозаполнения свер-сверхдлинного командного слова. 23-25 - это слишком много.
И еще один гвоздь в гроб эльбрустики. Экономический.Есть и еще одно неочевидное, но смертельное для «отечественных процессоров» следствие «своего пути»: хождение «своим путем»: придумывание и изготовление всего абсолютно с нуля, без использования чужих наработок - это очень долго и очень дорого. Чем выливается для конечного пользователя такое «натягивание совы на глобус», которым несколько десятилетий занимались сотни высокооплачиваемых специалистов? Тем, что такая «сова на глобусе» в магазине стоит совершенно дурных денег. Вычислительный комплекс «Эльбрус-401PC» имеет оглушительный ценник в 199000.00 р. Даже с учетом того, что там монитор на 23 дюйма в комплекте - это раза в четыре дороже, чем можно купить нормальный компьютер на платформе Intel или AMD. При этом, за свои деньги покупатель нормального компьютера получит еще и вчетверо (грубо) большую производительность. Т.о., «патриотизм» в вычислениях обойдется в шестнадцать (грубо) раз дороже, чем при использовании нормальных компьютеров. Я не думаю, что существует хоть сколько-нибудь заметное количество людей, готовых купить это за свои деньги. «Эльбрусы» принудительно распихают за бюджетные деньги в государственные и бюджетные учреждения. Разумеется, с учетом всех привходящих обстоятельств (несмешная производительность, падающая еще примерно вдвое при использовании знакомого ПО (х86/64) через режим динамической трансляции кода) и сложности с переносом имеющегося программного обеспечения - «патриотические компьютеры» будут использоваться только для показов начальству и отчетности. А работать будут на «вражеской» технике. ИТОГО: китайцы с нуля за двадцать лет заполучили современные микропроцессоры мирового уровня, практически без технологического риска, и сдается мне, что существенно дешевле, чем нам «Эльбрусы» обошлись. И у них перспектива открыта - а мы опять в тупике. Продать получившийся ущербный продукт можно только самим себе за свои деньги. Как из него выбираться? Перестать, наконец, ходить «своим путем», и отлицензировать ту же современную MIPS64. Люди, способные запустить трехмиллиарднотранзисторный Эльбрус-8С на 1300 мегагерц (тот же МЦСТ) - года за 2-3 сделают и десктопные MIPS64 камни на 100+ GFlops (настоящих, 64-разрядных) и серверные на 500+. Если, наконец, начать ехать по дороге, а не продираться через «суверенные» буераки VLIW, потому что это «традиция такая, предки так ездили».  Знаете, что на этой фотографии? На этой фотографии - ноутбук на процессоре Loongson 3A2000. Небольшой ноутбук с диагональю 13,3 дюйма, под управлением Linux, что естественно - и с производительностью свыше 150 GFlops. При том, что типовой ноутбук на i7 дает производительность в пределах сотни. Честно говоря, такое уже хочется купить для нормальной работы, а не просто как поиграть с экзотической хреновиной. P.S. В России сегодня тоже разрабатываются процессоры архитектуры MIPS32 и даже -64, но это крохотные низкочастотные (от 33 до 150 MHz) счетчики для встраиваемого и военного применения. Слово «Гигафлопс» в их присутствии произносить невежливо. Плакать будут.
| ||
| На главную страницу |
Главная | Справочник | FAQ | Статьи | Загрузки | Контакты | Конференция
 Хотя, в отличие от «Эльбрусов» - они-то вполне коммерчески успешны. Что намекает.
Хотя, в отличие от «Эльбрусов» - они-то вполне коммерчески успешны. Что намекает. 






- frontier -